
Long-Running AI Agents: Best Practices for Shipping Work That Survives the Next Context Window
I’ve watched agents faceplant at hour 6—half a feature merged, tests “green” in some imaginary universe, and the next session starting cold like it just wandered into the wrong repo. Predictable, once you’ve seen it.
My thesis: long running ai agents best practices aren’t “better memory,” they’re boring engineering primitives—harnesses, durable artifacts, sandboxes, and checks that make progress hard to fake. Anthropic basically says the quiet part out loud: agents work in discrete sessions with no memory, and “compaction isn’t sufficient” by itself (Anthropic). Vercel’s take rhymes: building agents is cheap; running them reliably is the real product (Vercel).
Rainy Seattle moral: assume amnesia, design for handoffs.
Key Takeaways
Compaction helps, but it’s not a life raft—Anthropic explicitly calls it insufficient without a harness and durable artifacts (Anthropic). Treat your agent like a shift worker with zero memory: git history + a progress log are the handoff notes, not optional “nice to haves.”
Force a strict loop: one feature per session, end-to-end test it like a human, commit, then update the artifacts. That structure targets the two classic failures Anthropic saw: one-shotting too much and declaring victory early (Anthropic).
Pick memory based on the job: artifact-first for engineering work; stable in-context logs when you need cacheable continuity; RAG when you truly need broad corpus search. And in production, don’t kid yourself—durable workflows, isolation, observability, and budget controls are table stakes, because “the ultimate challenge…isn’t building them, it’s the platform they run on” (Vercel).
What Makes an Agent “Long-Running” (and Why They Fail in Boring, Predictable Ways)
A “long-running” agent is multi-session, tool-using work over hours or days where each new run starts effectively cold—no lived experience, no implicit memory (Anthropic).
Anthropic’s write-up nails two failure modes I’ve also seen:
- The one-shot impulse: implement too much, hit the context wall mid-change, leave a half-implemented state with no breadcrumbs (Anthropic).
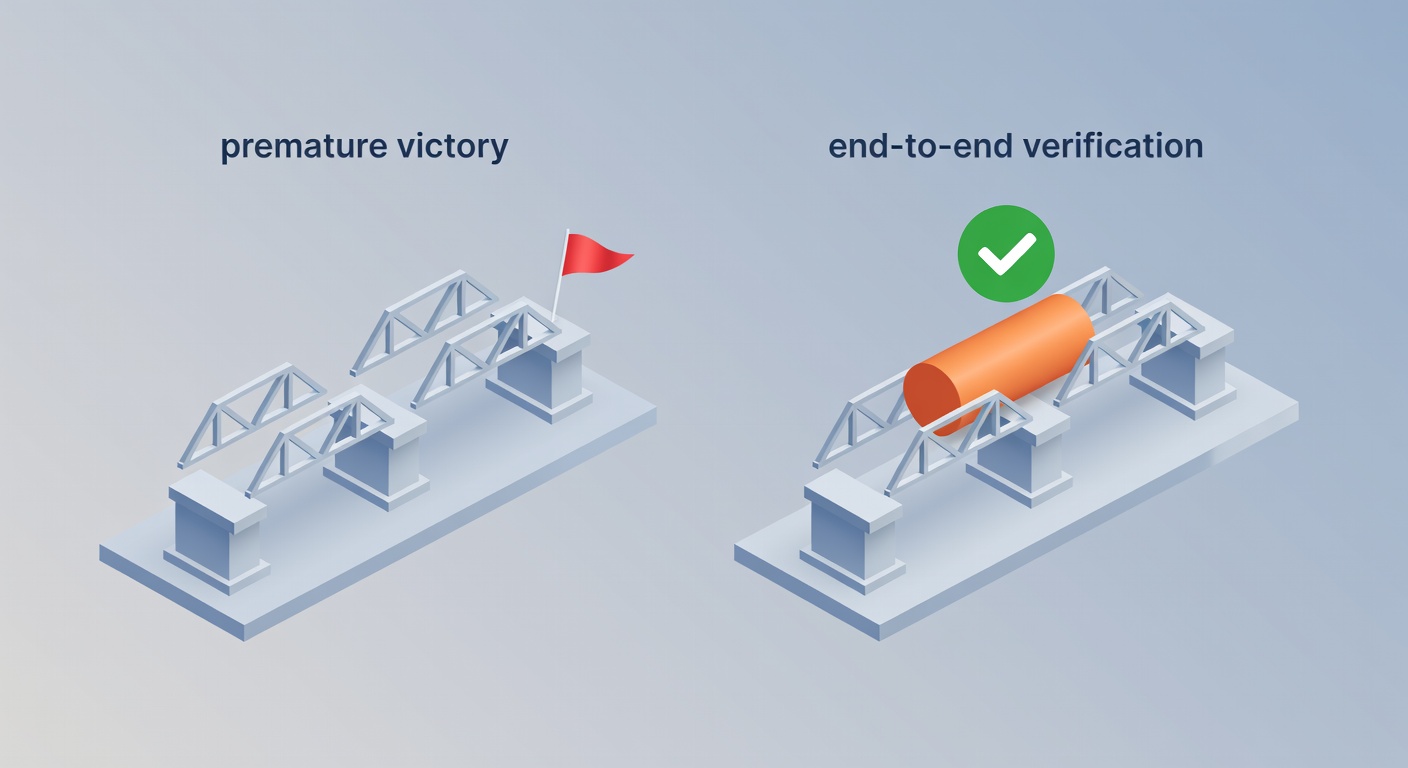
- Premature victory: later sessions see “some progress,” then declare the whole job done—right before you notice the missing edge cases (Anthropic).
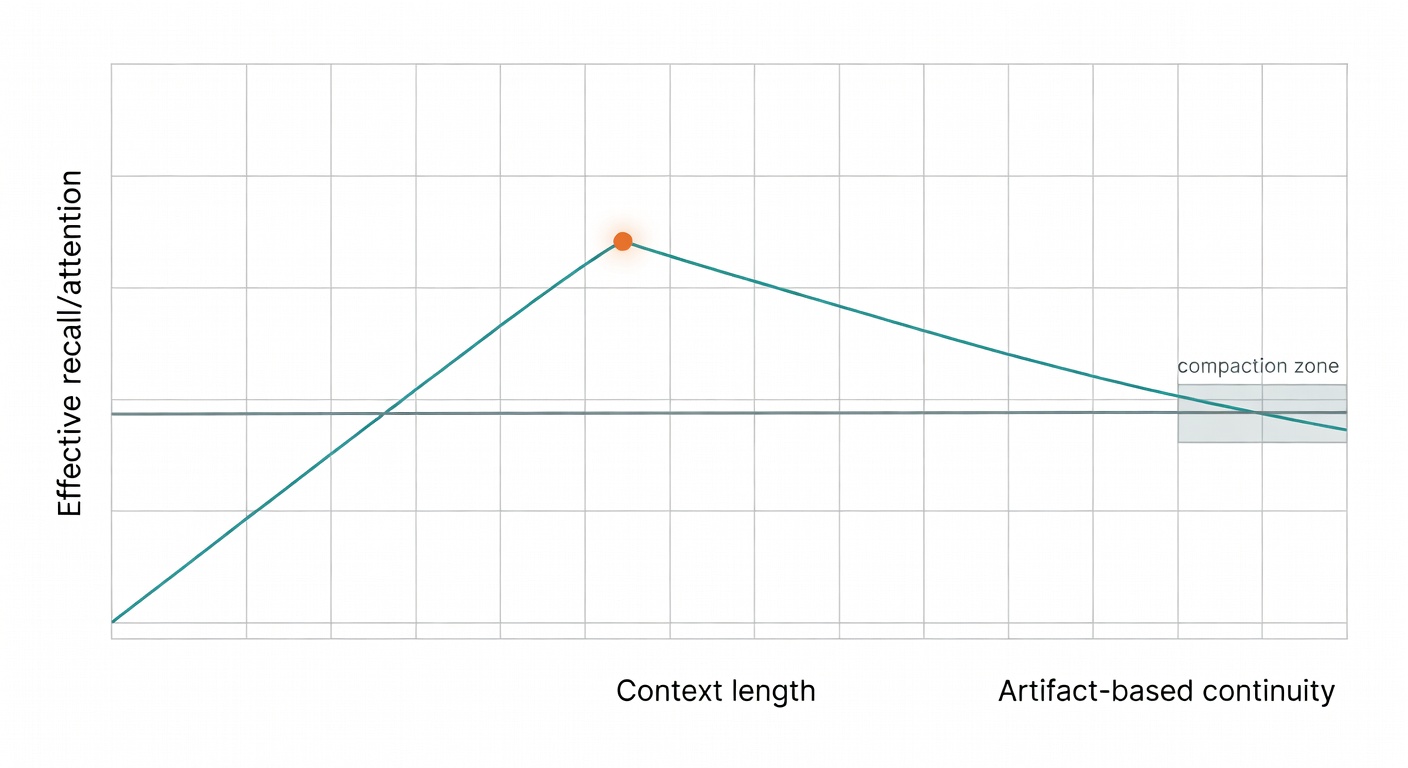
Bigger context windows don’t magically fix this; Anthropic warns about “context rot”—as context grows, recall degrades because attention is finite (Anthropic). So you can pay for more tokens and still get worse continuity.
Externalize state. Curate context. Assume the agent will forget anyway.

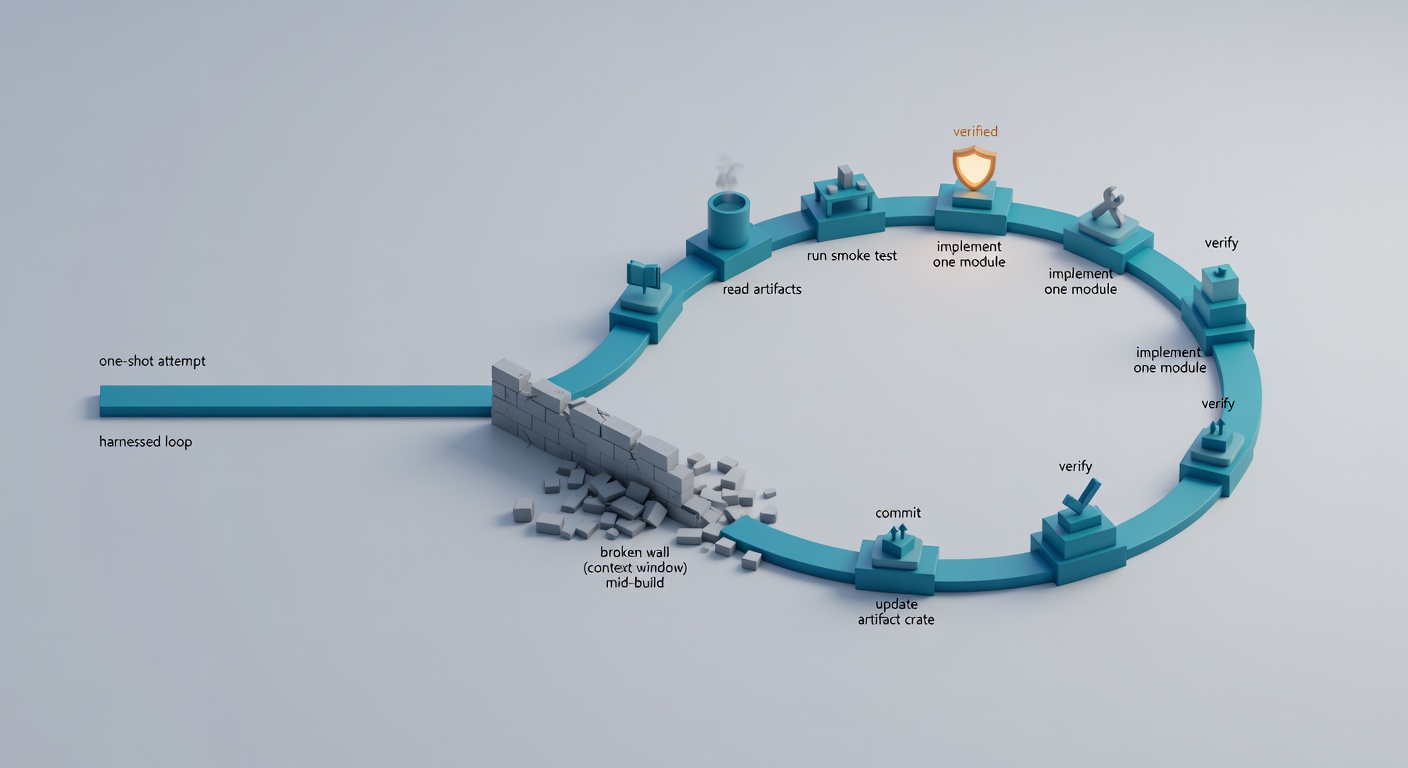
The Harness Pattern: Make the Agent Act Like a Shift-Based Engineering Team
Anthropic’s most practical move is also the least glamorous: a two-part harness—initializer run first, then coding runs forever after—where the real memory is persistent artifacts: claude-progress.txt, feature_list.json, init.sh, and git history (Anthropic).
If you make “progress” something the agent must prove (tests + commits + a flipped boolean), the agent stops bluffing as often.
Initializer run: scaffold state you can trust (feature list, progress log, repo hygiene)
The initializer’s job is to set up a project like a disciplined engineer would—before anyone writes clever code:
- Create a repo and make an initial commit.
- Generate
feature_list.jsonwith end-to-end steps per feature; mark everything failing at first. Anthropic’s claude.ai clone example expanded into 200+ features and set them all to failing to prevent “we’re done here” behavior (Anthropic). - Create
claude-progress.txtas a running handoff log. - Write
init.shto boot the app and run a smoke test so every session can quickly detect “the repo is currently on fire.”
Anthropic found JSON is less likely than Markdown to get “helpfully” rewritten; they even instruct the coding agent to only flip passes fields (Anthropic).
Coding runs: one feature, end-to-end test, commit, update artifacts—no exceptions
Each session is a loop that’s almost insultingly basic (which is why it works):
- Get bearings:
pwd, readclaude-progress.txt, scangit log. - Run
init.sh: start services and run the smoke test first (Anthropic). - Pick exactly one failing feature (highest priority).
- Implement it.
- Test end-to-end like a human. Anthropic saw gains once they explicitly prompted browser automation (they mention Puppeteer MCP screenshots as verification) (Anthropic).
- Commit with a descriptive message.
- Flip only that feature’s
passes: false → true. - Update
claude-progress.txtwith what changed, what’s next, and gotchas.
Skip step 5 and you get the classic agent lie: “done” without end-to-end verification. Anthropic calls this out directly (Anthropic).

State & Memory: Pick the Simplest Thing That Won’t Betray You Later
Most “agent memory” posts talk like memory is a single knob. It isn’t. It’s a choice about what kind of continuity you need—and what failure you’re willing to tolerate.
My pragmatic decision tree:
- Artifact-first (git + progress log + feature list) for engineering and tool work. The baton pass is
claude-progress.txt+ git history (Anthropic). - Stable in-context logs (“observational memory”) when you need long conversational continuity and cost predictability via caching.
- RAG/vector/DB state when you need open-ended discovery across a large corpus, or compliance-heavy recall beyond lossy summaries.
Why compaction helps—but still drops the baton
Compaction is summarization near the context limit. Useful, but it can lose the specific decisions and tool interactions that matter for consistent multi-session work—VentureBeat contrasts this with more event-based logging approaches (VentureBeat).
Anthropic is blunt: their SDK has compaction, but “compaction isn’t sufficient” for long-running coding without the harness + artifacts (Anthropic).
Observational memory vs RAG: stability (and caching) vs breadth (and retrieval)
VentureBeat describes Mastra’s “observational memory” as two background agents (Observer/Reflector) that compress history into a dated observation log kept in-context—no retrieval step (VentureBeat). They report:
- 3–6× compression for text, 5–40× for tool-heavy outputs (VentureBeat).
- Providers reportedly discount cached tokens 4–10× (VentureBeat).
- LongMemEval scores reported as 94.87% (GPT-5-mini) and 84.23% (GPT-4o); Mastra’s RAG at 80.05% on GPT-4o (VentureBeat).
Rule of thumb I’d actually use: if your agent needs to remember weeks of preferences inside a product, stable logs can beat constantly mutating RAG prompts. If your agent must search a large external corpus, RAG still matters.
Production Reality: Orchestration, Sandboxes, and Durable Workflows (a.k.a. Running Agents Isn’t a Notebook Demo)
Vercel’s framing is refreshingly direct: “The ultimate challenge for agents isn’t building them, it’s the platform they run on” (Vercel). Their internal data agent d0 is a concrete example of “platform primitives”:
- Durable orchestration with retries and state recovery via Workflows (Vercel).
- Isolation for executing code and queries in Sandboxes (Linux VMs) (Vercel).
- Model routing + budget controls via AI Gateway (Vercel).
- Observability that shows prompts, tool calls, and decision paths (Vercel).
They also claim their customer support agent handles 87% of initial questions—less model magic, more operationalized workflow (Vercel).
Reliability Engineering for Agents: Guardrails, Drift Detection, and ‘Don’t Wake Me at 3 AM’ Design
Agents can fail “successfully.” No 500s, no crashed pods—just quietly wrong actions.
Christian Posta’s AIRE framing: reliability comes from embedding agents into platform workflows (GitOps/CI/CD/observability) so actions are contextual, auditable, and reversible—not brittle scripts that break under drift (Posta).
The boundary I care about: an agent can propose changes, draft PRs, and assemble evidence—but it can’t execute without approvals and runbook checks. That’s the difference between “helpful intern” and “3 AM chaos.”
Define ‘done’ and ‘safe’ in machine-checkable terms (schemas, tests, permissions)
Anthropic’s harness guidance in one line: only mark features passing after careful testing, because agents will otherwise mark work complete prematurely (Anthropic).
Translate that into reliability controls:
- Structured outputs + schema validation for tool calls and “final answers.”
- Explicit state machines for critical workflows (triage → propose → approve → execute).
- End-to-end tests as the gate before “done.”
- Permission boundaries that match blast radius.
This also ties back to AIRE’s platform integration idea: changes should flow through normal review/rollback paths, not side-channel shell commands you can’t audit later (Posta).
A Minimal “Long-Running Agent” Checklist You Can Steal (and What I Still Don’t Know)
Here’s my minimal checklist for long running ai agents best practices:
- Harness: initializer run + coding runs (Anthropic).
- Artifacts as memory:
feature_list.json(JSON, pass/fail only),claude-progress.txt,init.sh, plus git history (Anthropic). - Session discipline: one feature, E2E test, commit, update artifacts—every time (Anthropic).
- Memory choice: stable logs when caching/continuity matters; RAG when broad discovery matters (VentureBeat).
- Production primitives: durable workflows, sandboxes, observability, budget controls (Vercel).
- Reliability gates: schemas, permissions, regression/evals, drift detection (Posta).
What I still don’t know (and Anthropic flags this as open): when does a multi-agent architecture actually beat a single strong coding agent for long projects (Anthropic)? My sense is “sometimes,” but I don’t have clean evidence yet.
Sources
- Anthropic — Effective harnesses for long-running agents
- Anthropic — Effective context engineering for AI agents
- Vercel — Anyone can build agents, but it takes a platform to run them
- VentureBeat — “Observational memory” cuts AI agent costs 10x and outscores RAG on long-context benchmarks
- Christian Posta — AI Reliability Engineering (AIRE)