TL;DR
This article clarifies the distinctions and overlaps between supervised, unsupervised, and reinforcement learning paradigms. It explains their data requirements, learning processes, and typical applications, with analogies from hardware engineering and software debugging. A deep dive into reinforcement learning algorithms highlights key techniques and challenges, while historical and industrial examples demonstrate RL’s practical impact. The post also addresses common misconceptions and encourages critical engagement with these foundational ML concepts.
Key takeaways
- Supervised learning uses labeled data to predict outputs, excelling in tasks like classification and regression but depends heavily on label quality.
- Unsupervised learning finds hidden patterns in unlabeled data, useful for clustering and dimensionality reduction, though evaluation is less straightforward.
- Reinforcement learning learns via interaction with an environment, optimizing cumulative rewards through trial and error, balancing exploration and exploitation.
- Key RL algorithms include Temporal-Difference learning, Monte Carlo methods, and eligibility traces, with function approximation techniques enabling scalability to complex state spaces.
- On-policy and off-policy learning differ in whether the policy being learned matches the policy used to generate data, affecting stability and flexibility.
- Historical milestones like TD-Gammon and Samuel’s Checkers Player showcase RL’s potential, while industrial applications demonstrate real-world benefits and challenges.
- Common pitfalls include confusing RL with supervised learning, underestimating data/computational needs, and neglecting reward design and exploration strategies.
People frequently think that I’m very stupid when I first admit that I found the distinctions between supervised, unsupervised, and reinforcement learning confusing—despite having a decade of engineering experience under my belt. Back in college and early career days, these terms felt like jargon tossed around without clear boundaries. Over time, through reading canonical texts and building small projects, I’ve come to appreciate the nuanced differences and overlaps among these paradigms. This post aims to clarify those distinctions with an evidence-driven approach, sprinkled with analogies from hardware engineering and personal anecdotes, to help enthusiasts and practitioners alike.
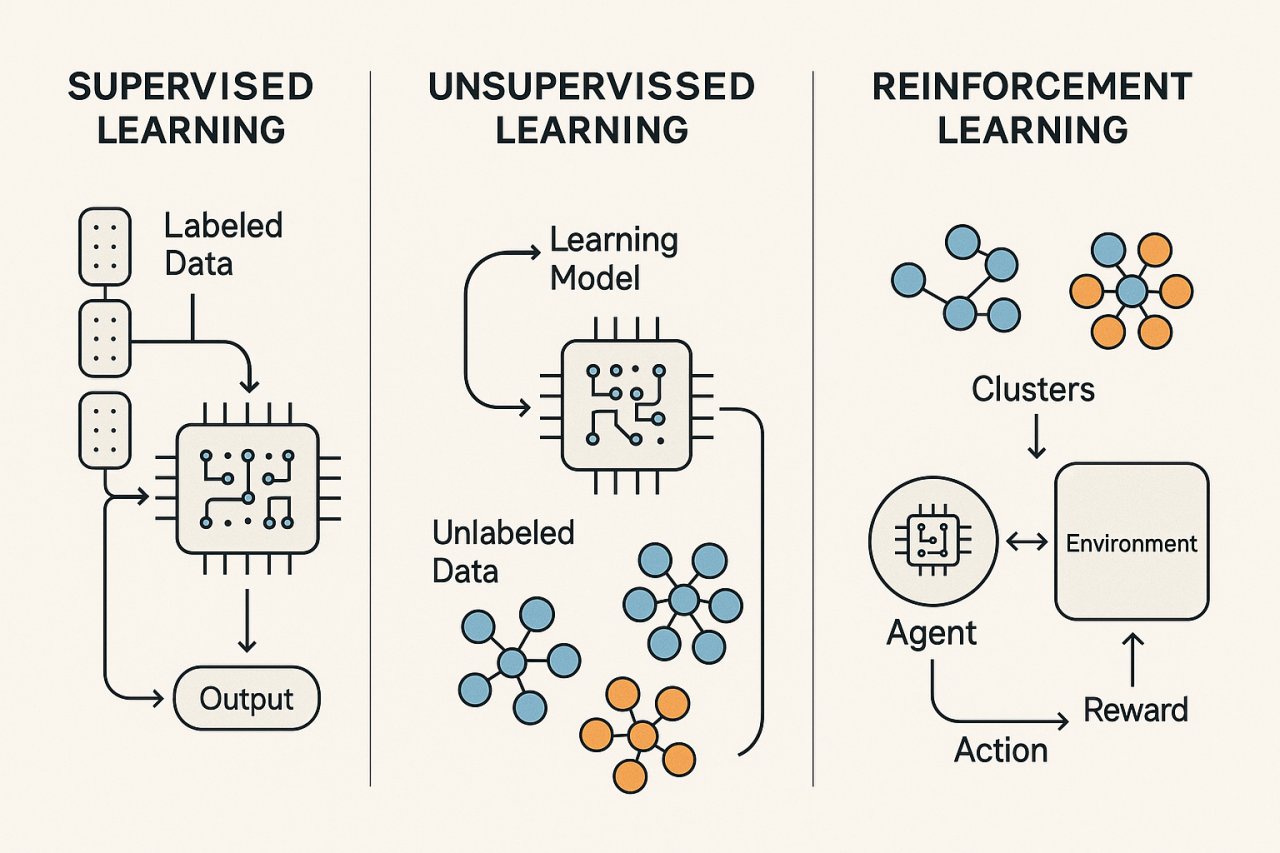
Overview of Machine Learning Paradigms
At a high level, machine learning (ML) can be categorized into three main paradigms:
- Supervised Learning: Learning from labeled data to predict outputs.
- Unsupervised Learning: Discovering patterns in unlabeled data.
- Reinforcement Learning (RL): Learning through interaction with an environment, maximizing cumulative reward.
These categories are well-established in the literature, notably in Sutton & Barto’s seminal textbook, Reinforcement Learning: An Introduction[^1]. Each paradigm addresses different problem settings and assumptions about data and feedback.
Supervised Learning: Learning from Labeled Data
Supervised learning involves training algorithms on datasets where each input is paired with a correct output label. Typical tasks include:
- Classification: Assigning inputs to discrete categories (e.g., spam detection).
- Regression: Predicting continuous values (e.g., house prices).
Common algorithms range from linear regression and decision trees to deep neural networks. To draw an analogy from CPU microarchitecture, supervised learning resembles a pipeline where labeled data flows through stages of feature extraction, transformation, and prediction, with feedback loops (loss gradients) guiding parameter updates—akin to branch predictors adjusting based on mispredictions.
However, label quality is a practical challenge. Noisy or incorrect labels can degrade performance, much like manufacturing defects in hardware causing subtle bugs downstream.
Unsupervised Learning: Discovering Patterns in Unlabeled Data
Unsupervised learning operates without explicit labels, seeking to uncover hidden structures such as clusters or associations. Examples include:
- Clustering: Grouping similar data points (e.g., customer segmentation).
- Dimensionality Reduction: Extracting meaningful features (e.g., PCA).
Evaluating unsupervised models is inherently tricky since there’s no ground truth. This exploratory nature is reminiscent of hardware defect detection, where engineers look for anomalies without predefined labels—patterns emerge from the data itself rather than from explicit supervision.
Reinforcement Learning: Learning by Interaction and Reward
Reinforcement learning is distinct in that an agent learns by interacting with an environment, receiving feedback in the form of rewards or penalties. The agent’s goal is to maximize cumulative reward over time, balancing exploration (trying new actions) and exploitation (leveraging known good actions).
The agent-environment loop is central:
- The agent observes a state.
- Chooses an action.
- Receives a reward and next state.
- Updates its policy accordingly.
Sutton & Barto emphasize RL as a computational approach to goal-directed learning[^1]. Historical milestones like TD-Gammon and Samuel’s Checkers Player illustrate RL’s potential and challenges. My own experience with trial-and-error debugging in software development echoes this iterative learning cycle.
Does that seem reasonable so far?
Key Contrasts Between the Paradigms
With the basics laid out, it’s worth contrasting these paradigms explicitly, acknowledging overlaps and edge cases.
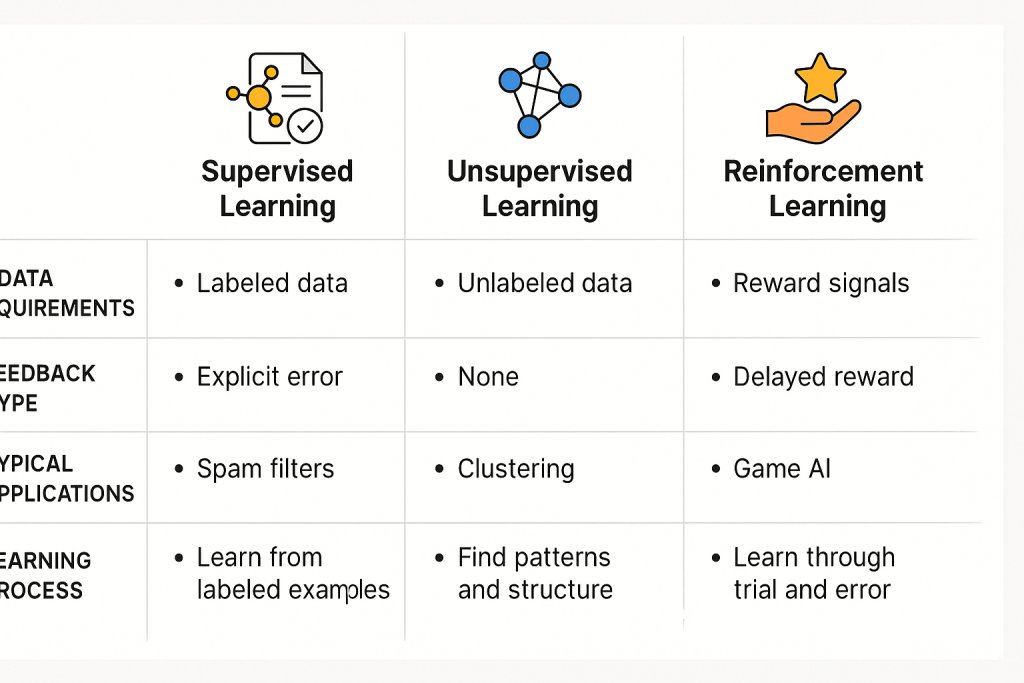
Data Requirements and Labels
- Supervised Learning: Requires large amounts of labeled data, which can be expensive and time-consuming to obtain[^2].
- Unsupervised Learning: Operates on unlabeled data, making it suitable when labels are scarce.
- Reinforcement Learning: Relies on reward signals rather than labels; these rewards may be sparse or delayed.
Learning Process and Feedback
- Supervised: Learns from explicit examples, adjusting based on prediction errors.
- Unsupervised: Finds hidden structure without explicit feedback.
- Reinforcement: Learns from delayed rewards through interaction, often requiring exploration strategies.
An analogy here is debugging: supervised learning is like fixing code with explicit test failures; unsupervised is inspecting logs for anomalies; RL is akin to deploying code and learning from user feedback over time.
Typical Applications and Use Cases
| Paradigm | Common Applications |
|---|---|
| Supervised Learning | Email spam filters, image recognition, recommendation engines[^3] |
| Unsupervised Learning | Customer segmentation, anomaly detection in hardware testing |
| Reinforcement Learning | Elevator dispatching, job-shop scheduling, game AI (e.g., TD-Gammon) |
Industry relevance is clear: for instance, Amazon reportedly attributes 35% of its sales to recommendation engines powered by supervised learning[^4].
If you’re still with me, the next section dives deeper into reinforcement learning algorithms, which often cause the most head-scratching.
Deep Dive: Reinforcement Learning Algorithms and Techniques
Reinforcement learning’s complexity often intimidates newcomers, but it’s worth unpacking key methods.1
Temporal-Difference Learning and Monte Carlo Methods
- Monte Carlo (MC) methods learn from complete episodes, averaging returns after the fact.2
- Temporal-Difference (TD) methods bootstrap by updating estimates after each step, improving sample efficiency.2
My own attempts to implement TD learning revealed how bootstrapping accelerates convergence but can introduce bias if not carefully managed.2
Eligibility Traces and Their Role
Eligibility traces blend MC and TD approaches, assigning credit to recently visited states or actions3. Sutton & Barto describe them as unifying these methods in a “valuable and revealing way.” However, tuning eligibility traces is subtle—too aggressive and learning becomes unstable, too conservative and convergence slows.
Function Approximation Techniques
When state spaces are large or continuous, function approximation is essential:2
- Tile Coding: Uses overlapping grids to represent features.
- Radial Basis Functions (RBF): Employs Gaussian kernels based on distance.
- Kanerva Coding: Uses binary features with Hamming distance.
These methods remind me of signal processing in hardw
are, where feature extraction filters complex inputs into manageable representations.
On-policy vs Off-policy Learning
- On-policy methods (e.g., Sarsa) learn about the policy currently being followed.2
- Off-policy methods (e.g., Q-learning) learn about a different policy, allowing more flexibility but often more instability.2
Understanding this distinction helps avoid common confusions in RL implementations.3
- Reinforcement Learning algorithms — an intuitive overview, SmartLab AI, 2019. Provides an accessible introduction to RL concepts and methods.
- Reinforcement Learning Algorithms: An Overview and …, arXiv, 2022. Comprehensive survey of RL algorithms and techniques including TD, MC, and function approximation.
- What is Reinforcement Learning?, AWS. Explains RL fundamentals, eligibility traces, and policy distinctions with practical insights.
Historical and Practical Applications of Reinforcement Learning
Games and Early Milestones
- TD-Gammon (1992–1995): Gerry Tesauro’s program learned backgammon at near world-champion level using TD learning and neural networks[^5].
- Samuel’s Checkers Player (1950s–1960s): One of the first to use heuristic search combined with TD learning[^6].
These successes shaped RL’s trajectory, demonstrating that trial-and-error learning can rival human expertise.
Industrial Optimization Examples
- Jack’s Car Rental: RL optimized car rental operations by learning demand patterns[^7].
- Elevator Dispatching: RL improved scheduling in multi-elevator systems, reducing wait times[^8].
- Dynamic Channel Allocation: Cellular networks used RL to reduce call blocking[^9].
- Job-Shop Scheduling: RL found efficient job schedules in manufacturing[^10].
While promising, these applications also highlight RL’s challenges: model complexity, reward design, and computational cost.
Statistical and Market Context
As of 2025-09-11, the AI/ML market is booming:
- Demand for AI/ML specialists is expected to grow by over 80% by 2030[^11].
- The global machine learning market was valued at $19 billion in 2022, projected to reach $188 billion by 2030[^12].
- Reinforcement learning’s impact includes a reported 40% reduction in energy spending at Google data centers[^13].
That said, some claims are inflated or lack nuance, so a skeptical eye is warranted.
Projected Demand Growth for AI/ML Specialists (2025-2030) (percent)
Global Machine Learning Market Value (2020-2030) (Billion USD)
Common Misconceptions and Pitfalls
I’ve personally stumbled over these:
- Confusing reinforcement learning with supervised learning, assuming RL requires labeled data.
- Underestimating the data and computational needs of RL algorithms.
- Overlooking the importance of reward shaping and exploration strategies.
Recognizing these pitfalls early can save a lot of wasted effort.
Expert quotes
“Reinforcement learning is learning what to do—how to map situations to actions—so as to maximize a numerical reward signal.”
Richard S. Sutton & Andrew G. Barto, University of Alberta — Reinforcement Learning: An Introduction
“Reinforcement learning algorithms enable agents to learn optimal behaviors through trial and error interactions with a dynamic environment.”
Caltech AI & Machine Learning Group — What is Reinforcement Learning in AI?
“Mission-ready reinforcement learning focuses on deploying RL systems that can operate reliably in real-world, safety-critical applications.”
MIT Lincoln Laboratory — Mission-Ready Reinforcement Learning
Conclusion and Reflections
Supervised, unsupervised, and reinforcement learning each serve distinct roles in the ML landscape, with unique assumptions, challenges, and applications. While supervised learning dominates many practical deployments, RL’s promise in sequential decision-making is compelling but complex. Unsupervised learning remains crucial for exploratory data analysis.
Open questions remain, especially around scaling RL to real-world problems and integrating paradigms. I encourage readers to engage critically, experiment, and share insights.
Thanks to Sophia Wisdom and others for comments, corrections, and discussion. If you have corrections or think I’m wrong, please let me know.
Acknowledgements and Further Reading
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction[^1].
- Coursera’s Machine Learning Specialization[^14].
- DeepLearning.AI’s Reinforcement Learning courses[^15].
- Data Science Texts’ curated RL book list[^16].
- Manning’s recent ML books[^17].
Postscript: Joining the Conversation
If you’re interested in diving deeper, consider joining communities like the Recurse Center[^18], where writing and speaking about complex topics is encouraged. Starting a blog or coding small RL projects can solidify understanding. My own journey benefited greatly from such environments.
[^1]: Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press. Link
[^2]: IBM. (2023). The cost and scarcity of labeled data in industry.
[^3]: GeeksforGeeks. (2024). Supervised vs Unsupervised vs Reinforcement Learning.
[^4]: Introduction to Machine Learning in Conversion Optimization.
[^5]: Tesauro, G. (1995). TD-Gammon, a self-teaching backgammon program.
[^6]: Samuel, A. L. (1959). Some Studies in Machine Learning Using the Game of Checkers.
[^7]: Sutton & Barto (2018), Jack’s Car Rental example.
[^8]: Sutton & Barto (2018), Elevator Dispatching example.
[^9]: Sutton & Barto (2018), Dynamic Channel Allocation example.
[^10]: Sutton & Barto (2018), Job-Shop Scheduling example.
[^11]: AWS Certified Machine Learning Specialty. (2024).
[^12]: IBM Market Report (2023).
[^13]: Neptune Blog. (2023). RL impact on Google Data Centers.
[^14]: Coursera Machine Learning Specialization.
[^15]: DeepLearning.AI Reinforcement Learning Course.
[^16]: Data Science Texts. Recommended RL Books.
[^17]: Manning Publications. Recent ML Titles.
[^18]: Recurse Center. (2025). Community for programmers and writers.
If you have corrections or think I’m wrong, please let me know. As always, feedback is welcome.